
Релейная ЭВМ версия 2. Релейная логика. Сумматор с параллельным переносом
Привет, давно не виделись. Я вернулся к проекту релейной ЭВМ и хочу представить на суд продолжение этой темы.
UPDATE: Снял видео из цикла BrainfuckPC. Дабы не плодить новую статью, добавлю его сюда:


Каждое реле имеет некоторую задержку срабатывания и отпускания, которое мы примем за 1 условную единицу времени(у.е.в.) Если будем использовать реле РЭС22, 1у.е.в. будет равен 12-15мс (справочное), РЭС64 — 1.3мс(справочное). Самой дорогой операцией в АЛУ моей машины является сумматор.
Сумматор сам по себе довольно простой и быстрый, но «есть один нюанс», который заключается в способе вычисления и передачи сигнала переноса.
Изначально я планировал использовать сумматор с последовательным переносом. В таком сумматоре каждый последующий разряд зависит от состояния сигнала переноса разряда текущего. В итоге длительность операции вычисления будет колебаться между 2 у.е.в. — N*2 у.е.в., где N — число разрядов. В итоге, 8-разрядный сумматор с последовательным переносом будет иметь максимальную задержку 12 у.е.в.

Рисунок 1: Принципиальная схема 4-разрядного сумматора с последовательным переносом
Такой вариант меня не устроил, поэтому будем проектировать сумматор с параллельным переносом. Так как сумматоров в системе будет как минимум два — сумматор в АЛУ и сумматор текущей команды (Instruction Pointer — IP) (не хочу отдавать его на откуп микроконтроллеру), задачка становится еще более актуальной. Сумматор в АЛУ будет 8-разрядным, сумматор IP — 16-разрядным.
Уравнение суммирования можно описать с помощью логической операции XOR:
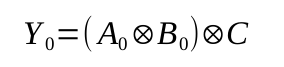
И в релейной схеме выглядеть вот так:
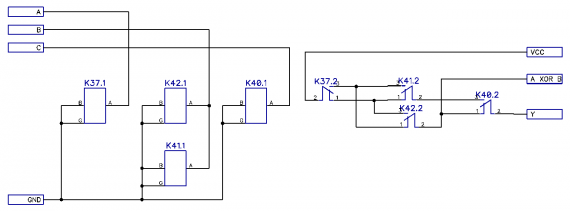
Рисунок 2: Принципиальная схема сложения с переносом
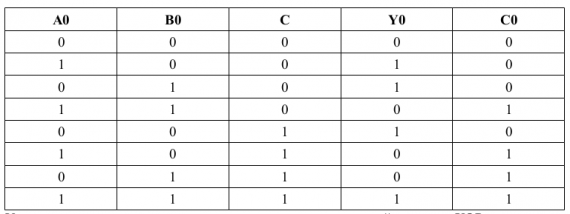
Как видно из рисунка, операция суммирования с переносом требует 4 реле типа РЭС55 на разряд. Это число является постоянным для любого числа разрядов. Итого на сумматор АЛУ нам потребуется 32 реле, на сумматор IP — 64 реле.
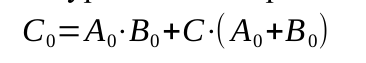
Приняв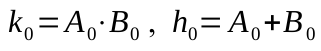 получим
получим
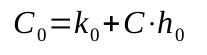
Следующий разряд будет зависеть от предыдущего:
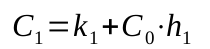
Разворачивая и подставляя до посинения, получаем:
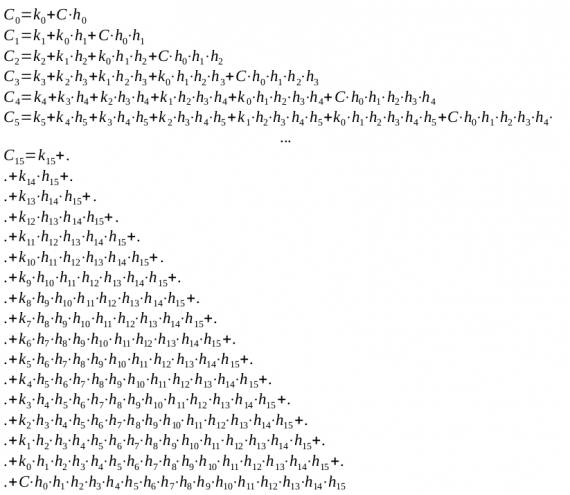
Как говорится, ничто не предвещало бури.
Давайте посчитаем во сколько реле нам это встанет.
2AND можно организовать двумя путями:
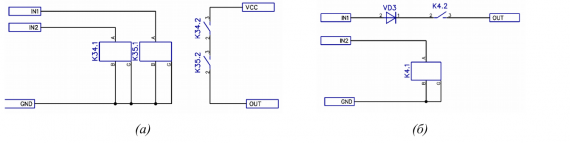
Рисунок 3: Принципиальная схема логического AND — с полной развязкой (а) и частичной (б)
Общая черта логического И представленного на рисунке 3а, б заключается в масштабировании — без особо труда можно добавить дополнительный вход без усложнения коммутационной схемы. Отличие в том, что для создания логического AND на N входов схеме на рисунке 3а потребуется N реле РЭС64, в то время как для схемы на рисунке 3б — (N-1).
Логическое ИЛИ организовывается так:
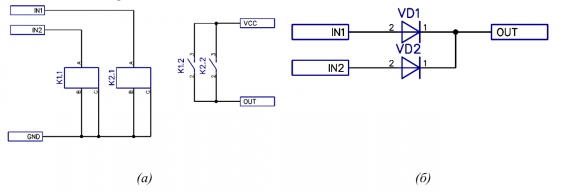
Рисунок 4: Принципиальная схема логического OR с полной развязкой (а) и ее отсутствием (б)
Схема на рисунке 4.а представляет собой классическое OR на реле и обладает неоспоримым преимуществом — полностью развязывает вход от выхода. Зато вторая схема совершенно не требует реле и главное — не имеет задержки срабатывания ( задержка конечно есть, но на порядки меньшая чем у реле и про нее можно даже не думать). С другой стороны, на диоде падает целый 1 Вольт напряжения, что для релейной схемы с питанием 5-6В может быть критично.
Обе схемы требуют N элементов для создания N-разрядного OR.
Подсчитаем общее количество реле, требуемых для переноса в 16-разрядном счетчике.
1. Для развязки сумматора на входе поставим полностью развязанные 2 AND и 2 OR, в количестве 16 штук каждый. Итого — 32 реле + 32 реле.
2. на перенос 16 разряда возьмем минимизированные схема AND и OR. Итого:
Хьюстон, у нас проблемы. На один только перенос потребуется около тысячи реле. Хотя погодите, а что если мы сделаем многовходовый AND с промежуточными выходами (рисунок 5).
В этом случае для переноса 16-го разряда мы сравним число диодов с количеством реле — 136 диодов, но при этом из него можно будет получить и все младшие разряды переноса просто забирая нужный разряд с многовходового AND. Более того, многовходовое логическое OR, в силу наличия диодов развязки в многовходовом AND, вовсе не будет содержать диодов.
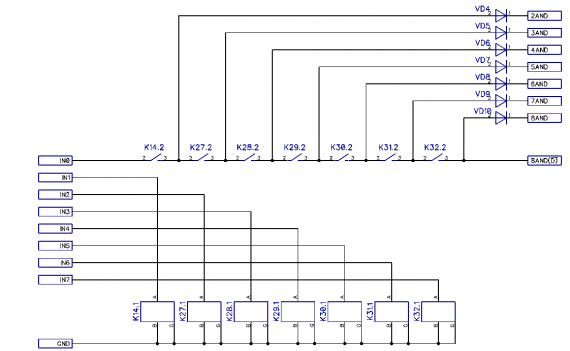
Рисунок 5: Принципиальная схема 8-разрядного И с промежуточными выходами. Бездиодный выход нужен для стекирования элементарных блоков
Подводим подсчеты:
Итоговая схемка 8-разрядного сумматора с параллельным переносом:
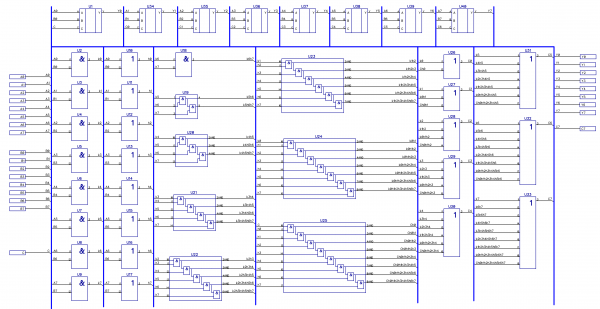
Рисунок 6: Принципиальная схема 8-разрядного сумматора с параллельным переносом. Вон те 8 блоков сверху — сумматор. Все остальное — схема переноса
Вся работа может быть изучена в репозитории на GitHub:
https://github.com/radiolok/RelayComputer2
В скором времени буду заказывать печатные платки и начну сие собирать.
UPDATE: Снял видео из цикла BrainfuckPC. Дабы не плодить новую статью, добавлю его сюда:
Введение
Релейная ЭВМ должна быть не только релейной, но еще и быстрой. Как и любая другая ЭВМ, моя РЦВМ будет синхронной машиной, оснащенной тактовым генератором. Естественно мне не хочется растрачивать впустую циклы тактирования и постараться каждую операцию уместить в один цикл — т. е. за нарастающий и спадающий фронты синхронного генератора успеть загрузить новую команду и исполнить ее. Желательно при этом чтобы все команды выполнялись за одинаковый период времени.Каждое реле имеет некоторую задержку срабатывания и отпускания, которое мы примем за 1 условную единицу времени(у.е.в.) Если будем использовать реле РЭС22, 1у.е.в. будет равен 12-15мс (справочное), РЭС64 — 1.3мс(справочное). Самой дорогой операцией в АЛУ моей машины является сумматор.
Сумматор сам по себе довольно простой и быстрый, но «есть один нюанс», который заключается в способе вычисления и передачи сигнала переноса.
Изначально я планировал использовать сумматор с последовательным переносом. В таком сумматоре каждый последующий разряд зависит от состояния сигнала переноса разряда текущего. В итоге длительность операции вычисления будет колебаться между 2 у.е.в. — N*2 у.е.в., где N — число разрядов. В итоге, 8-разрядный сумматор с последовательным переносом будет иметь максимальную задержку 12 у.е.в.
Рисунок 1: Принципиальная схема 4-разрядного сумматора с последовательным переносом
Такой вариант меня не устроил, поэтому будем проектировать сумматор с параллельным переносом. Так как сумматоров в системе будет как минимум два — сумматор в АЛУ и сумматор текущей команды (Instruction Pointer — IP) (не хочу отдавать его на откуп микроконтроллеру), задачка становится еще более актуальной. Сумматор в АЛУ будет 8-разрядным, сумматор IP — 16-разрядным.
Схема суммирования
Рассмотрим таблицу истинности схемы суммирования двух бит с переносом:Уравнение суммирования можно описать с помощью логической операции XOR:
И в релейной схеме выглядеть вот так:
Рисунок 2: Принципиальная схема сложения с переносом
Как видно из рисунка, операция суммирования с переносом требует 4 реле типа РЭС55 на разряд. Это число является постоянным для любого числа разрядов. Итого на сумматор АЛУ нам потребуется 32 реле, на сумматор IP — 64 реле.
Параллельный перенос
По таблице истинности составим уравнение операции переноса:Приняв
получимСледующий разряд будет зависеть от предыдущего:
Разворачивая и подставляя до посинения, получаем:
Как говорится, ничто не предвещало бури.
Давайте посчитаем во сколько реле нам это встанет.
2AND можно организовать двумя путями:
Рисунок 3: Принципиальная схема логического AND — с полной развязкой (а) и частичной (б)
Общая черта логического И представленного на рисунке 3а, б заключается в масштабировании — без особо труда можно добавить дополнительный вход без усложнения коммутационной схемы. Отличие в том, что для создания логического AND на N входов схеме на рисунке 3а потребуется N реле РЭС64, в то время как для схемы на рисунке 3б — (N-1).
Логическое ИЛИ организовывается так:
Рисунок 4: Принципиальная схема логического OR с полной развязкой (а) и ее отсутствием (б)
Схема на рисунке 4.а представляет собой классическое OR на реле и обладает неоспоримым преимуществом — полностью развязывает вход от выхода. Зато вторая схема совершенно не требует реле и главное — не имеет задержки срабатывания ( задержка конечно есть, но на порядки меньшая чем у реле и про нее можно даже не думать). С другой стороны, на диоде падает целый 1 Вольт напряжения, что для релейной схемы с питанием 5-6В может быть критично.
Обе схемы требуют N элементов для создания N-разрядного OR.
Подсчитаем общее количество реле, требуемых для переноса в 16-разрядном счетчике.
1. Для развязки сумматора на входе поставим полностью развязанные 2 AND и 2 OR, в количестве 16 штук каждый. Итого — 32 реле + 32 реле.
2. на перенос 16 разряда возьмем минимизированные схема AND и OR. Итого:
- 17 OR — 0реле 17 диодов,
- 16 AND — 15 реле 1 диод,
- 15 AND — 14 реле 1 диод,
- 14 AND — 13 реле 1 диод,
- 13 AND — 12 реле 1 диод,
- 12 AND — 11 реле 1 диод,
- 11 AND — 10 реле 1 диод,
- 10 AND — 9 реле 1 диод,
- 9 AND — 8 реле 1 диод,
- 8 AND — 7 реле 1 диод,
- 7 AND — 6 реле 1 диод,
- 6 AND — 5 реле 1 диод,
- 5 AND — 4 реле 1 диод,
- 4 AND — 3 реле 1 диод,
- 3AND — 2 реле 1 диод,
- 2AND — 1 реле 1 диод.
Хьюстон, у нас проблемы. На один только перенос потребуется около тысячи реле. Хотя погодите, а что если мы сделаем многовходовый AND с промежуточными выходами (рисунок 5).
В этом случае для переноса 16-го разряда мы сравним число диодов с количеством реле — 136 диодов, но при этом из него можно будет получить и все младшие разряды переноса просто забирая нужный разряд с многовходового AND. Более того, многовходовое логическое OR, в силу наличия диодов развязки в многовходовом AND, вовсе не будет содержать диодов.
Рисунок 5: Принципиальная схема 8-разрядного И с промежуточными выходами. Бездиодный выход нужен для стекирования элементарных блоков
Подводим подсчеты:
- 16-Разрядный сумматор
- Схема суммирования — 64 реле, 1 у.е.в.
- Буферные элементы — 64 реле, 1 у.е.в.
- Схема вычисления переноса — 136 реле, 136 диодов, 1 у.е.в.
- ИТОГО: 264 реле, 136 диодов, задержка 2у.е.в.
- 8-Разрядный сумматор
- Схема суммирования — 32 реле, 1 у.е.в.
- Буферные элементы — 32 реле, 1 у.е.в.
- Схема вычисления переноса — 36 реле, 36 диодов, 1 у.е.в.
- ИТОГО: 100 реле, 36 диодов, задержка 2у.е.в.
Итоговая схемка 8-разрядного сумматора с параллельным переносом:
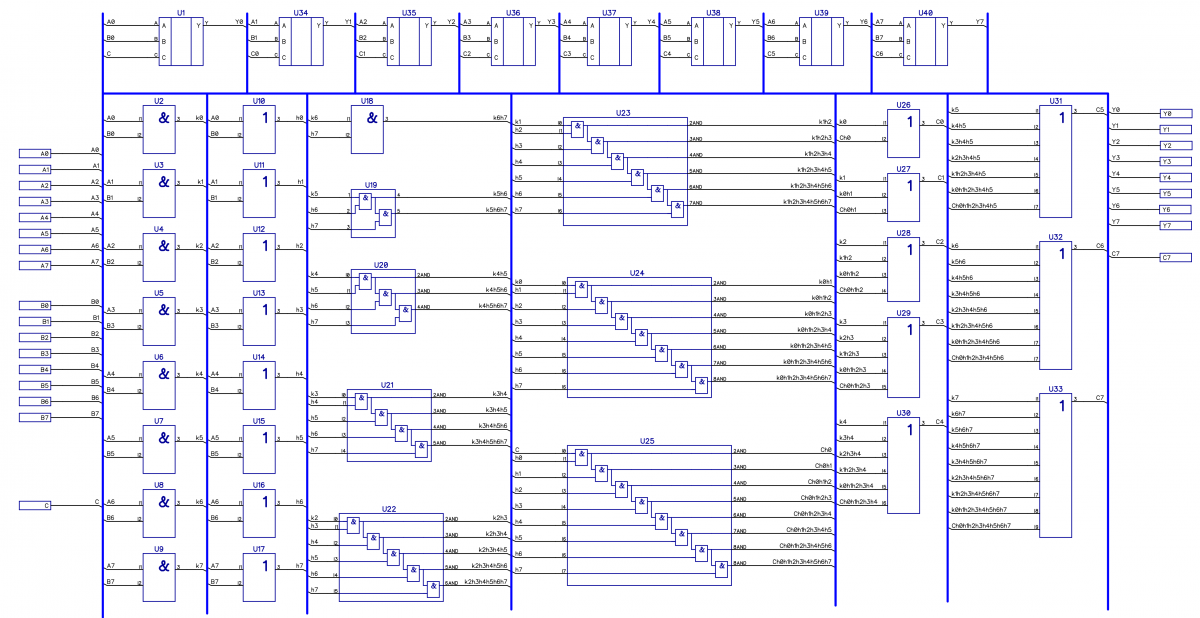
Рисунок 6: Принципиальная схема 8-разрядного сумматора с параллельным переносом. Вон те 8 блоков сверху — сумматор. Все остальное — схема переноса
Вся работа может быть изучена в репозитории на GitHub:
https://github.com/radiolok/RelayComputer2
В скором времени буду заказывать печатные платки и начну сие собирать.
7 комментариев
Параллельный сумматор — это круто, хотя этоже демокомп, задача которого просто щелкать. Тут можно было и попроще сумматор заиспользвоать.
Но, в любом случае, реквестирую память программ на ферритовых сердечниках.
Вот например 16-разрядный сумматор с параллельным переносом. На 32 унифицированных модулях. 248 реле. Это уже финальный вариант. С15 отсутствует за ненадобностью.
Сижу заказываю на али всякую мелочевку и в бой. Платы буду делать сам. Заодно вспомню как паяльная маска делается.
А память на ферритах — да где-бы контроллер взять! На ebay полно модулей 16х16, да контроллеров с адекватной ценой нема. Я вон 50к сердечников за 30 долларов купить могу и сам матрицы нашить, но управлять чем?
ЦМД-шки еще можно типа вот таких https://www.155la3.ru/k1602.htm но у этих встает вопрос где взять их и контроллер на них. На ebay встречаются bubble-memory но конских ценников.
HP 5060-8331, устанавливался в компьютеры HP 2100A
цена в рублях. контроллера нет, но зато драйвер на месте.
Если серьёзно – очень ядрёная штука, моей силы воли даже на ЭВМ из 74-й логики не хватило, тоже когда-то делал. :)
Кстати – какое еще планируется железо кроме АЛУ? По ПЗУ смотрю уже пошли обсуждения. :)
P.S.
Will it run Crysis? :D
Пока блок памяти будет целиком на SRAM. у меня есть SRAM-кэш от 386-го или первопня: um61512ak-15 две штуки как раз 128Кб дадут. Загрузчик программы в первой итерации будет внешний, через МК.
Ферритовое ПЗУ с загрузчиком уже потом подключу, ибо Х его З как это делается :) Пока только подготовлю логику чтобы можно было страницы по 4Кб разных типов памяти ставить. Типа первые 8кслов — ПЗУ, следующие ОЗУ, потом внешняя шина и т.д.
Да, это вдобавок еще и Фон-Нейман :) Но с учетом только одного вычислительного блока суперскаляра от меня не дождетесь :) Хотя реализация предполагает израсходование только половины от имеющихся у меня запасов герконовых реле :) Другая половина ХЗ куда…
Изготовление начну, как ни странно — с модуля памяти. Так как там будет shadow MCU и 16 входов и выходов, что идеально для реализации отладочного логического анализатора.