
DE0-Nano Cистема на кристалле. Часть 1
Всем привет! Заметил в сообществе определенный интерес к плисинам, поэтому решил зарегистрироваться и поделиться некоторыми своими домашними наработками на отладочной плате Terasic DE0-Nano.

Собственно на самой плате из интересных вещей, помимо микросхемы ПЛИС имеется SDRAM память, 8-канальный 12-разрядный АЦП ADC128S022 и встроенный USB blaster. В небольшом проекте, который я и опишу в статье, происходит оцифровка входного сигнала с одного из каналов АЦП, данные пишутся во внешнюю память в режиме DMA, а после того, как оцифровано достаточное количество отсчетов, данные передаются компьютер, где с ними можно будет чего-нибудь сделать, например, посмотреть спектр. В качестве канала передачи информации используется USB-JTAG, т.к. других средств на плате-то и нет)
По-сути, данный проект, представляет собой систему на кристалле, поэтому создание прошивки для ПЛИС, в данном случае, включает два основных момента:
— написание модуля для чтения данных с АЦП, который оформляется в виде IP-ядра. В дальнейшем созданный периферийный блок будет подключаться к шине Avalon.
— создание системы на кристалле в SOPC Builder(Часть среды Quartus II).
Схема всего этого хозяйства выглядит так:
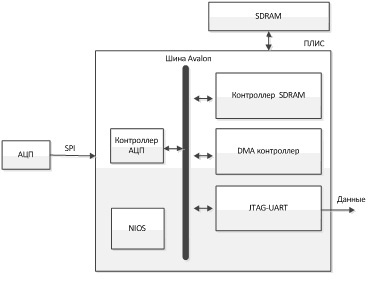
NIOS на рисунке, если кто не знает, это 32-битный soft-процессор, который будет выполнять задачу обработки прерываний от контроллера АЦП, а также запуск DMA.
Разработку я, разумеется, начал с самого просто, с контроллера АЦП. Формат передачи данных следующий:
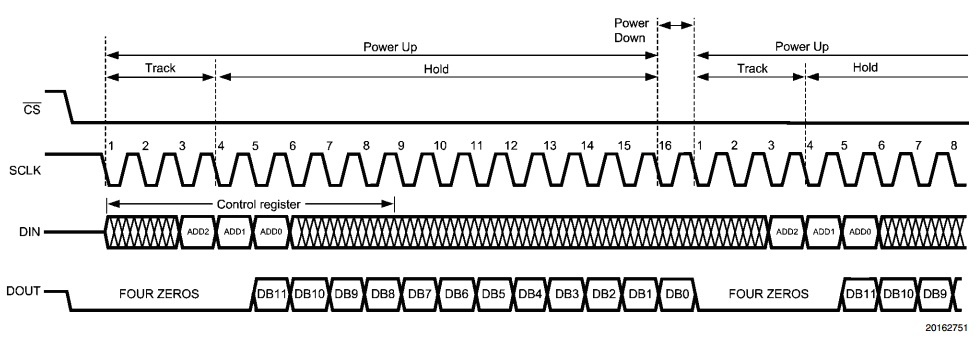
Сначала передаётся номер канала, с которого оцифровываем сигнал, затем нули. В это же время на линии DOUT устанавливаются значения c АЦП. Для описания я использую VHDL.
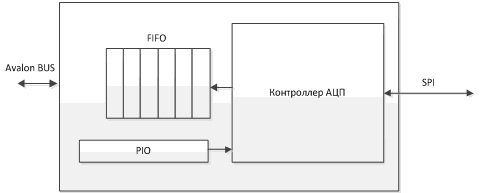
В итоговом IP-ядре, помимо контроллера АЦП, также присутствует очередь для временного хранения данных перед записью в SDRAM и блок с программно-доступными регистрами, через который из процессора NIOS можно будет взаимодействовать c ядром. Заголовок контроллера АЦП выглядит следующим образом:
entity adc_stream is
generic (
DIV_CLK: natural:=8
);
port (
clk: in std_logic; -- входная тактовая частота
reset: in std_logic; --сброс
convert: in std_logic; --запуск
channel: in std_logic_vector(2 downto 0); --канал
adc_sample: out std_logic_vector(15 downto 0); --выходные данные от АЦП
adc_new_sample: out std_logic; --строб новых данных
--SPI сигналы
miso: in std_logic;
mosi: out std_logic;
cs: out std_logic;
scl: out std_logic
);
end entity adc_stream;
GENERIC DIV_CLK задаёт в данном случае коэффициент деления входного тактового сигнала и, в конечном счете, скорость работы SPI и частоту дискретизации. Вся логика работы реализована при помощи двух процессов.
Во втором процессе реализован конечный автомат spi_fsm, отвечающий за запуск АЦП. В состоянии IDLE автомат ждет сигнал convert, для того, чтобы начать оцифровку. В состоянии TRANSFER, происходит непосредственное взаимодействие с микросхемой АЦП. Сам SPI реализован на сдвиговых регистрах, один на прием и один на передачу. Соответственно rx_shift_reg и tx_shift_reg. Convert_counter – счетчик для защелкивания готовых данных из сдвигового регистра в выходной порт и для формирования строба нового сэмпла adc_new_sample. Таким образом, получаем импульс на каждый новый отсчет сигнала. По перепаду данного сигнала также будет происходить запись данных в FIFO. Итоговый код выглядит следующим образом:
library ieee;
library work;
use ieee.std_logic_1164.ALL;
use ieee.numeric_std.ALL;
entity adc_stream is
generic (
DIV_CLK: natural:=8
);
port (
clk: in std_logic; -- входная тактовая частота
reset: in std_logic; --сброс
convert: in std_logic; --запуск
channel: in std_logic_vector(2 downto 0); --канал
adc_sample: out std_logic_vector(15 downto 0); --выходные данные от АЦП
adc_new_sample: out std_logic; --строб новых данных
--SPI сигналы
miso: in std_logic;
mosi: out std_logic;
cs: out std_logic;
scl: out std_logic
);
end entity adc_stream;
architecture arc of adc_stream is
--Тип для конечного автомата
type spi_fsm_t is (IDLE,TRANSFER);
signal clk_i: std_logic;
signal clk_counter: integer range 0 to 255 := 0;
signal convert_counter: integer range 0 to 16 := 0;
signal scl_i: std_logic;
--сдвиговые регистры
signal tx_shift_reg: std_logic_vector(15 downto 0);
signal rx_shift_reg: std_logic_vector(15 downto 0);
signal spi_fsm: spi_fsm_t;
begin
--Делитель входной частоты
process
begin
wait until rising_edge(clk);
if reset = '1' then
clk_i <= '0';
clk_counter <= 0;
else
if clk_counter = DIV_CLK then
clk_i <= not clk_i;
clk_counter <= 0;
else
clk_counter <= clk_counter+1;
end if;
end if;
end process;
process(reset, clk_i)
begin
if reset = '1' then
spi_fsm <= IDLE;
tx_shift_reg <= (others => '0');
rx_shift_reg <= (others => '0');
convert_counter <= 0;
mosi <= '1';
cs <= '1';
else
if rising_edge(clk_i) then
case spi_fsm is
--ожидание сигнала старта
when IDLE =>
if convert = '1' then
spi_fsm <= TRANSFER;
scl_i <= '1';
--старшие биты слова это номер канала
tx_shift_reg(13 downto 11) <= channel;
convert_counter <= 0;
end if;
when TRANSFER =>
if convert = '0' then
spi_fsm <= IDLE;
cs <= '1';
else
cs <= '0';
end if;
scl_i <= not scl_i;
if scl_i = '1' then
mosi <= tx_shift_reg(15);
tx_shift_reg <= tx_shift_reg(14 downto 0)&tx_shift_reg(15);
rx_shift_reg <= rx_shift_reg(14 downto 0)&miso;
--доступен новый отсчет
if convert_counter = 1 then
adc_sample <= rx_shift_reg;
adc_new_sample <= '1';
else
adc_new_sample <= '0';
end if;
if convert_counter = 16 then
convert_counter <= 1;
else
convert_counter <= convert_counter + 1;
end if;
end if
end case;
end if;
end if;
end process;
scl<= scl_i;
end architecture arc;
Для временного хранения данных, как я уже написал ранее, используется очередь, которая также обеспечивает перевод данных в другой тактовый домен шины Avalon, поскольку DMA контроллер использует шину для перекачки данных. Сгенерировать очередь с требуемыми параметрами можно с помощью Mega Wizard Plug-In Manager.
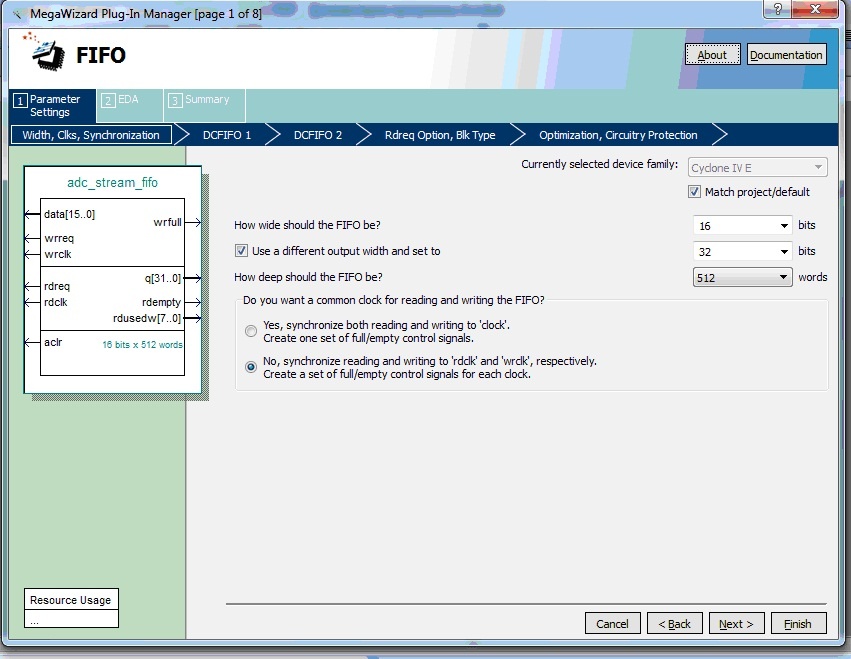
На первой странице выбираем разные значения ширины шины, 16 бит на запись, поскольку АЦП 12 разрядный, дополним старшие биты нулями, и 32 бита на чтение.
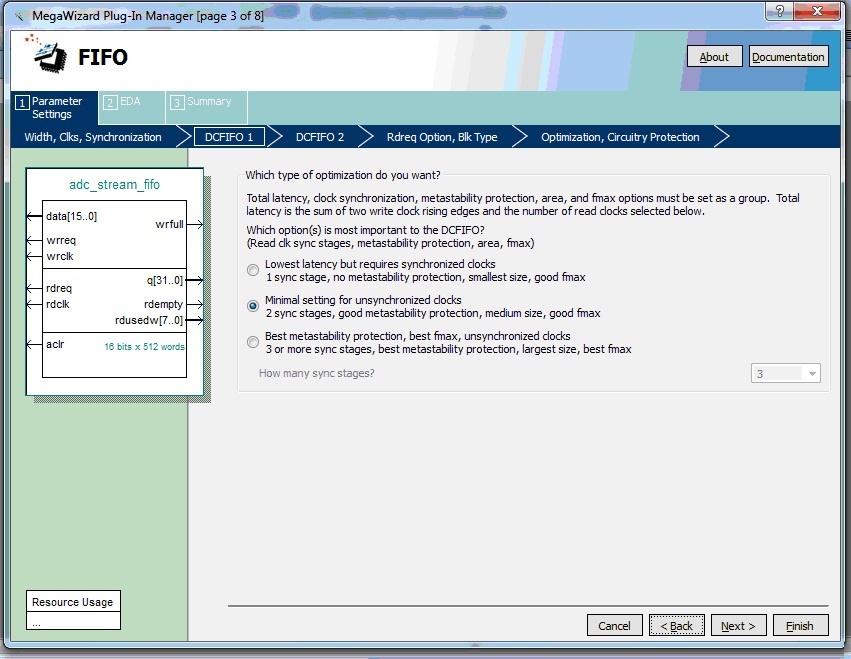
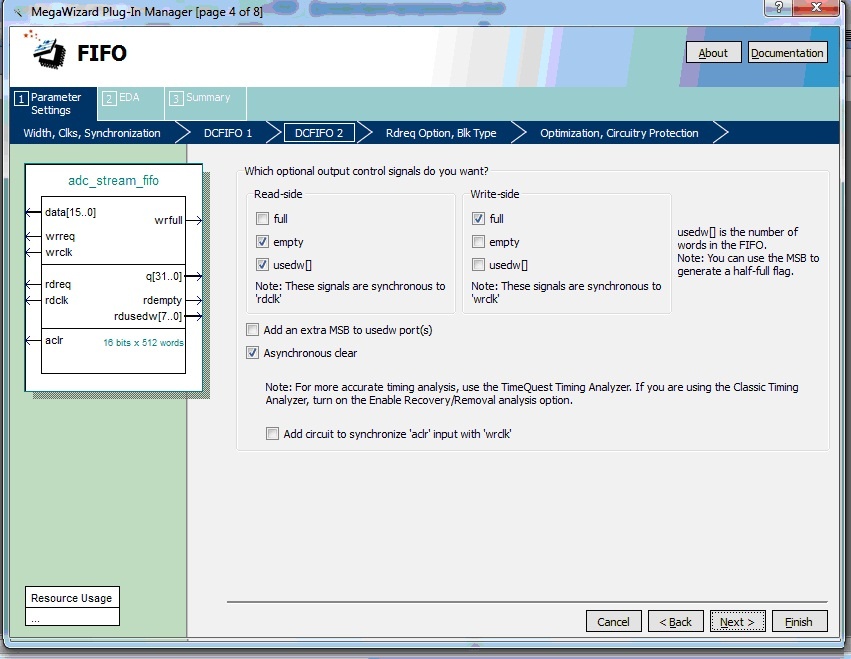
На третьей странице нужно выбрать необходимые флаги, которые будут анализироваться процессором NIOS. Параметр usedw[] – порт, который будет содержать количество слов, доступных для чтения. На остальных страницах можно оставит всё без изменения. В результате будет сформирован файл adc_stream_fifo.vhd, который мы впоследствии вставим в модуль контроллера АЦП.
Теперь необходимо оформить top-модуль adc_stream_top, который включит в себя блок контроллера АЦП и очередь. Модуль также будет содержать порты для подключения к шине Avalon, для использования в SOPC Builder в качестве периферийного узла. Заголовок модуля имеет следующий вид:
entity adc_stream_top is
generic
(
PIO_REG_COUNT: integer :=4 --количество программно доступных регистров
);
port
(
clk: in std_logic; --тактовая частота шины Avalon
reset: in std_logic; --сброс
--интерфейс spi
miso: in std_logic;
mosi: out std_logic;
cs: out std_logic;
scl: out std_logic;
--сигналы шины avalon
pio_address: in std_logic_vector(7 downto 0); --адрес регистра
pio_read: in std_logic; --запрос на чтение
pio_readdata:out std_logic_vector(31 downto 0); --данные из регистра
pio_write: in std_logic; --запрос на запись
pio_writedata: in std_logic_vector(31 downto 0); --данные для записи в регистр
pio_irq: out std_logic; --сигнал прерывания
--Интерфейс для DMA канала
dma_read: in std_logic; --запрос на чтение данных
dma_readdata: out std_logic_vector(31 downto 0) --данные из очереди
);
В заголовке определены, по сути, две шины Avalon, одна для программного доступа к управляющим регистрам, вторая для передачи данных к контролеру памяти в режиме DMA.
4 комментария
Еще, неплохо бы если бы вы описали что такое Avalon, как с ней работать и какие сигналы должна выдавать периферия, ну, или, хотябы, ссылку на документацию — далеко не каждый знает что это такое.
Интересно, почему VHDL? Не самый популярный язык нынче.
Ну и немного не по теме — а в чем рисовались картинки? Здоровски выглядят.
VHDL, потому что, у нас на работе используют только его, вот и пришлось изучать)
p.s. Картинки рисовал в microsoft visio