
Числа с фиксированной запятой
Расчеты в наших устройствах не всегда (мягко говоря) бывают целочисленными, а использовать числа с плавающей запятой (float или double) — весьма ресурсозатратно и не всегда корректно. Что же делать?
Есть несколько вариантов. К примеру, можно использовать отмасштабированные числа. Если нужно измерять вольты, то можно представить значения в милливольтах. Таким образом, мы получим и целое число и точные расчеты. Если не хватает милливольт, можно использовать микровольты, и так далее.
Такой подход часто используется в разных CADах и финансовой сфере. К примеру, в KiCad, расстояния измеряются в нанометрах и хранятся в int'ах (отсюда, кстати. максимальный размер платы — 4*4 метра).
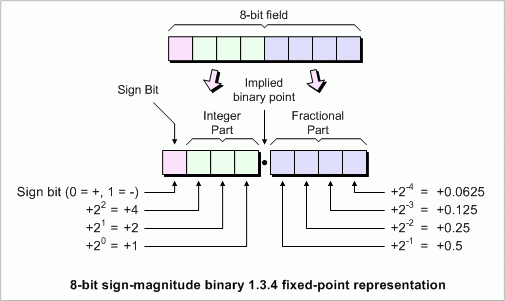
Часто представить величину в разных масштабах не особо хочется (к примеру, на индикаторе нужно отображать целую часть числа, а дробная часть служит только для повышения точности расчетов), и вот тогда приходится использовать числа с фиксированной запятой. Число с фиксированной запятой — это те-же целые числа, но, условно, под дробную часть выделено некоторое количество бит. Давайте, к примеру, из 32-битного целого числа сделаем несколько чисел с фиксированной запятой:

Как видно, числа с фиксированной запятой обозначают как qm.n, где m — целая часть, а n — дробная. Если число должно быть со знаком, то бит для знака отбирают у целой части. О знаковости числа косвенно говорит отсутствие одного бита в названии. К примеру:

Так, как хранить числа с фиксированной запятой мы будем в обычных целочисленных контейнерах, можно определить их вот так:
Примеры:
q16.16: максимальное число: 65535.99998474.., шаг — 1.53e-5
q0.32: максимальное число: 0.9999999997671..., шаг — 2.328e-10
q5.27: максимальное число: 31.9999999925..., шаг — 7.45e-9
Вот, к примеру, макросы для такого преобразования:
Если вы преобразовываете целое число, то можно не умножать, а просто сдвигать, так как умножение на степени двойки — это тот-же сдвиг, но вариант с умножением — более общий:
Для обратного преобразования, как не странно, мы сдвигаем наше число обратно.
Можно преобразовать и в число с плавающей запятой:
Для преобразование числа из одного положения фиксированной запятой в другое, его нужно сдвинуть на разницу в количестве дробный бит:
А вот для умножения и деления нам понадобится контейнер в два раза большего размера для хранения промежуточного результата, ведь при умножении 32 бит на 32 бита может получиться 64 бита:
Кстати, если вам нужно разделить на 10, или любую другую константу, можно заставить препроцессор посчитать 1/10, а потом — умножать на это число. Такой финт ушами позволяет сильно ускориться на процессорах без аппаратного делителя. К примеру:
Если вам нужно умножить или разделить на целое число, то можно делать эту операцию прямо на месте, без никаких сдвигов и преобразований
Более эффективными способами умножения и деления поделился nevier в комментариях.
Для того, чтобы сдвиги происходить быстро, в процессоре должен быть так называемый barrel-shifter. barrel-shifter — это кусок АЛУ, которая позволяет сдвигать числа на любое количество бит за один такт.
Часто, barrel-shifter эмулируется умножителем. К примеру, чтобы сдвинуть число влево на 3 бита, его можно просто умножить на 8.
Есть еще одна хитрость. Если под дробную часть отвести количество бит кратное 8, то процессор может просто выбрать байты со смещением и не использовать сдвигов вообще. Это особенно актуально, если числа разрадность процессора меньше разрядности используемого числа (к примеру, 32-битные числа на AVR).
Для того, чтобы такое не происходило, очень часто используют числа с нулевым количеством целых бит. К примеру, q0.32. Так как при умножении числа меньше единицы на число меньше единицы всегда будет число меньше единицы, переполнение q0.32 при умножениях просто невозможно.
При сложении, числа с фиксированной запятой ведут себя точно так-же, как и обычные целые числа.

После того, как такая возможность появилась, отладка стала значительно легче.
Есть несколько вариантов. К примеру, можно использовать отмасштабированные числа. Если нужно измерять вольты, то можно представить значения в милливольтах. Таким образом, мы получим и целое число и точные расчеты. Если не хватает милливольт, можно использовать микровольты, и так далее.
Такой подход часто используется в разных CADах и финансовой сфере. К примеру, в KiCad, расстояния измеряются в нанометрах и хранятся в int'ах (отсюда, кстати. максимальный размер платы — 4*4 метра).
Часто представить величину в разных масштабах не особо хочется (к примеру, на индикаторе нужно отображать целую часть числа, а дробная часть служит только для повышения точности расчетов), и вот тогда приходится использовать числа с фиксированной запятой. Число с фиксированной запятой — это те-же целые числа, но, условно, под дробную часть выделено некоторое количество бит. Давайте, к примеру, из 32-битного целого числа сделаем несколько чисел с фиксированной запятой:
Как видно, числа с фиксированной запятой обозначают как qm.n, где m — целая часть, а n — дробная. Если число должно быть со знаком, то бит для знака отбирают у целой части. О знаковости числа косвенно говорит отсутствие одного бита в названии. К примеру:
Так, как хранить числа с фиксированной запятой мы будем в обычных целочисленных контейнерах, можно определить их вот так:
typedef uint32 fx16q16_t;
typedef uint32 fx5q27_t;Максимальные и минимальные значения
У любого числа есть максимальные и минимальные значения. Максимальное значение для числе с фиксированной запятой — 2^m-1/(2^n-1), а минимальный шаг 1/(2^n-1). (тут, по прежнему, m — целая часть, а n — дробная)Примеры:
q16.16: максимальное число: 65535.99998474.., шаг — 1.53e-5
q0.32: максимальное число: 0.9999999997671..., шаг — 2.328e-10
q5.27: максимальное число: 31.9999999925..., шаг — 7.45e-9
Преобразование в число с фиксированной запятой и обратно
Для того, чтобы преобразовать число с плавающей запятой в число с фиксированной, нужно просто умножить его на 2^n.Вот, к примеру, макросы для такого преобразования:
#define fx16q16_make(a) ((fx16q16_t)((a) * (1LL<<16)))
#define fx5q27_make(a) ((fx5q27_t)((a) * (1LL<<27)))Если вы преобразовываете целое число, то можно не умножать, а просто сдвигать, так как умножение на степени двойки — это тот-же сдвиг, но вариант с умножением — более общий:
#define fx16q16_make(a) ((fx16q16_t)((a)<<16))
#define fx5q27_make(a) ((fx5q27_t)((a)<<27))Для обратного преобразования, как не странно, мы сдвигаем наше число обратно.
#define fx16q16_uint16(a)((uint16)((a) >> 16))
#define fx5q27_uint8(a) ((uint8)((a)>>27))Можно преобразовать и в число с плавающей запятой:
#define fx16q16_float(a) ((a) / (float)(1LL<<16))Для преобразование числа из одного положения фиксированной запятой в другое, его нужно сдвинуть на разницу в количестве дробный бит:
#define fx16q16_to_fx5q27(a) ((fx5q27_t)a<<11)Сложение, вычитание, умножение
Сложение и вычитание числе с фиксированной запятой точно такое-же, как и у целых чисел. Можно даже не определять макросы для этогоfx16q16_make(5)+fx16q16_make(8)==fx16q16_make(13)
fx16q16_make(18)-fx16q16_make(4)==fx16q16_make(14)
А вот для умножения и деления нам понадобится контейнер в два раза большего размера для хранения промежуточного результата, ведь при умножении 32 бит на 32 бита может получиться 64 бита:
#define fx16q16_mul(a,b) ((fx16q16_t)(((int64_t)(a) * (b)) >> 16))
#define fx16q16_div(a,b) ((fx16q16_t)(((int64_t)(a) << 16) / (b)))
Кстати, если вам нужно разделить на 10, или любую другую константу, можно заставить препроцессор посчитать 1/10, а потом — умножать на это число. Такой финт ушами позволяет сильно ускориться на процессорах без аппаратного делителя. К примеру:
fx16q16_t result = fx16q16_mul(number_to_divide_by_10, fx16q16_make(1.0f/10.0f))Если вам нужно умножить или разделить на целое число, то можно делать эту операцию прямо на месте, без никаких сдвигов и преобразований
fx16q16_t mul_by_5 = fx_number * 5
fx16q16_t div_by_5 = fx_number / 5
Более эффективными способами умножения и деления поделился nevier в комментариях.
Скорость
Естественно, главная причина, по которой мы работаем с этими числами — скорость. Для эффективной работы, нам понадобится очень много сдвигов.Для того, чтобы сдвиги происходить быстро, в процессоре должен быть так называемый barrel-shifter. barrel-shifter — это кусок АЛУ, которая позволяет сдвигать числа на любое количество бит за один такт.
Часто, barrel-shifter эмулируется умножителем. К примеру, чтобы сдвинуть число влево на 3 бита, его можно просто умножить на 8.
Есть еще одна хитрость. Если под дробную часть отвести количество бит кратное 8, то процессор может просто выбрать байты со смещением и не использовать сдвигов вообще. Это особенно актуально, если числа разрадность процессора меньше разрядности используемого числа (к примеру, 32-битные числа на AVR).
Переполнениия
Как и другие числа, числа с фиксированной запятой можно переполнить. К примеру:fx16q16_make(300)*fx16q16_make(300) = 0Для того, чтобы такое не происходило, очень часто используют числа с нулевым количеством целых бит. К примеру, q0.32. Так как при умножении числа меньше единицы на число меньше единицы всегда будет число меньше единицы, переполнение q0.32 при умножениях просто невозможно.
При сложении, числа с фиксированной запятой ведут себя точно так-же, как и обычные целые числа.
Отладка
Отладка фиксированных запятых может быть очень заковыристой, потому, что вместо простого и понятного «5», в отладчике вы увидите «327680». К счастью, многие программы умеют показывать вычисленные результаты в watch-окне. К примеру, в IAR'е можно написать:После того, как такая возможность появилась, отладка стала значительно легче.
17 комментариев
Как ваирант, можно включать и выключать ножку и смотреть на осциллографе.
Раз у вас 7 тактов, то, возможно, ваш компилятор вставляет что-то еще. К примеру, реально читает BSRR из GPIOA.
Вот дизассемблер:
Нужно 4 умножения 16х16=>32 бита.
Деление q16:
Хоть оно и побитовое, но работает в разы бsстрее, чем х64 деление на Cortex-m3. Может быть можно сделать еще быстрее используя аппаратное деление 32/32=>32 и алгоритм Кнута.
Добавил в статью. И еще добавил про умножения на целые числа.
Отличная статья!